Derniers Articles
Google Search Console ouvre enfin les données de vos posts Instagram, TikTok, X et YouTube Google muscle ses règles sur les avis en ligne et prévient des sanctions manuelles Goossips SEO : Robots.txt [Evénement] Un apéro Web à Nantes le 30 juillet, pour networker avant les vacances IA agentique : pourquoi vos données personnelles vous échappent un peu plus chaque jour Bruxelles sanctionne Google à hauteur de 890 millions d’euros pour non-respect du DMA Google face à la fronde des grands médias : plusieurs éditeurs envisagent le blocage Crawl Budget : Google met à jour sa documentation Google contre SerpApi : le tribunal rejette la plainte, mais l’affaire n’est pas terminée Google lance officiellement les AI Overviews en France !Lire l'article complet : Grounding Budget : Comment Google limite la taille des contenus pour l’IA Search
Publié le 07/01/2026 à 08:33:21 par Abondance
Grounding Budget : Comment Google limite la taille des contenus pour l’IA Search
Google ne lit pas vos pages en entier pour générer ses réponses IA, même si elles font 3 000 mots. Les travaux de Dan Petrovic montrent l’existence d’un budget de grounding d’environ 2 000 mots par requête, réparti entre quelques sources seulement, avec un avantage net pour les pages les mieux classées. Ce qui change tout pour la stratégie de contenu : la densité d’information compte davantage que la longueur.
Ce qu'il faut retenir :
- Google dispose d’un budget d’environ 2 000 mots de grounding par requête, partagé entre 3 à 5 sources principales.
- La position dans le classement détermine la part de ce budget : la source #1 reçoit environ deux fois plus de texte que la #5.
- Au niveau d’une page, la sélection plafonne aux alentours de 540 mots ; au-delà de 1 500–2 000 mots, les gains sont marginaux.
- Les pages concises et très ciblées obtiennent un taux de couverture bien supérieur aux pavés de 4 000 mots : densité > longueur.
D’où viennent les chiffres ?
Dan Petrovic a analysé un large corpus de requêtes réelles pour comprendre comment Google alimente ses systèmes Gemini en contenu issu du web. L’étude porte sur 7 060 requêtes comptant au moins trois sources, comparant les extraits de grounding réellement envoyés au modèle avec le contenu complet de 2 275 pages tokenisées.
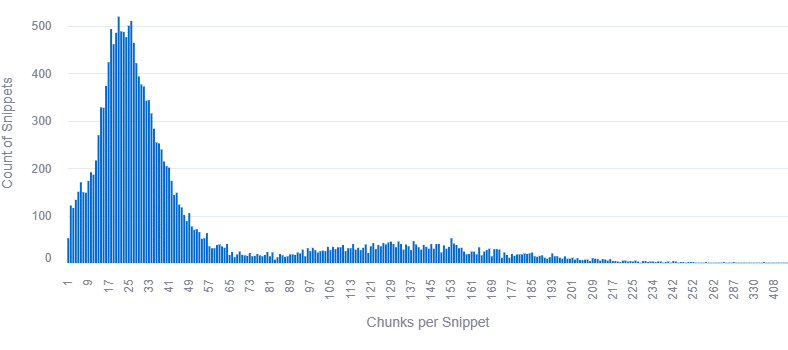
Le jeu de données comprend 883 262 extraits (snippets), avec une moyenne de 15,5 mots par chunk, et une statistique détaillée des longueurs de chunks (mots, caractères, mots par chunk). Pour observer le grounding, Dan n’essaie pas de « deviner » les extraits : il regarde les segments exacts fournis au modèle comme contexte avant génération, ce qui permet une correspondance précise avec le texte source.
Le budget de grounding : environ 2 000 mots par requête
Premier constat majeur : chaque requête semble disposer d’un budget de grounding total d’environ 2 000 mots, quelle que soit la longueur des pages sources. Les percentiles de mots totaux par requête se situent ainsi : p25 = 1 546, médiane = 1 929, p75 = 2 325, p95 = 2 798.
Ce budget est remarquablement stable : ajouter plus de sources ne multiplie pas le volume de texte total envoyé à l’IA, il est simplement redistribué entre davantage de documents. Dan précise que ces 2 000 mots correspondent à une médiane, avec quelques cas extrêmes allant jusqu’à environ 5 000 mots et un échantillon autour de 30 000 mots qu’il soupçonne d’être un bug dans sa pipeline.
Comment Google répartit ce budget entre les sources ?
L’étude montre que la variable déterminante est le rang de la source dans les résultats de recherche, et non la longueur du contenu. Le budget global est partagé selon la position dans les SERPs, avec la répartition médiane suivante :
- Rang #1 : 531 mots, soit 28 % du budget total
- Rang #2 : 433 mots,...