Derniers Articles
SEO + GEO : un nouveau livre blanc pour comprendre les LLM et mieux les influencer IA générative et métiers du web : quelles compétences pour les nouveaux entrants ? Google Discover sur Minecraft.fr : 16 mois de data décortiqués Référencement local et secteur automobile : comment un réseau comme AD tire parti du SEO pour ses 2 300 garages ? « Tailor Your Feed » : le fan-out Discover qui fait émerger les sites de niche Comment un agent IA gère votre blog de A à Z : le cas Alya de Sedestral Google publie un guide officiel sur les outils SEO tiers et met à jour sa documentation Vers un Publisher Center 2.0 ? Google officialise les profils étendus Google casse la géolocalisation des SERPs : vos données de ranking sont-elles fiables ? La SEO Garden Party est de retour le 18 juin 2026 !Lire l'article complet : Google Discover sous le capot : 20 pipelines, des millions de cartes, des insights inédits issus de la data.
Publié le 30/03/2026 à 14:09:38 par Abondance
Google Discover sous le capot : 20 pipelines, des millions de cartes, des insights inédits issus de la data.
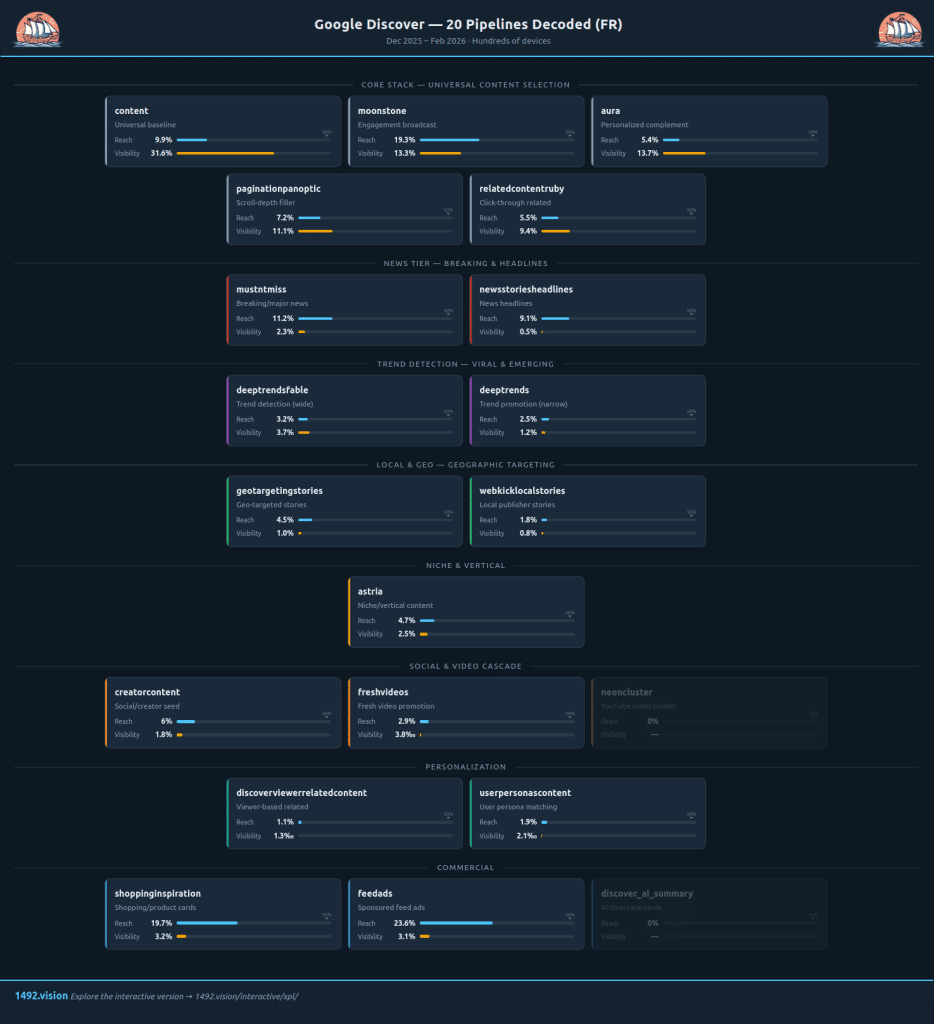
L'analyse SDK de Metehan Yesilyurt a révélé les noms des pipelines internes de Google Discover. Nos données montrent ce que chacun fait réellement : volume, portée, timing, domaines leaders. 42 millions de cartes, des centaines d'appareils, trois mois d'observation.
Ce qu'on a fait
Pendant trois mois (décembre 2025 - février 2026), nous avons observé les flux Discover réels de centaines d'appareils. Résultat : 42 millions de cartes analysées. A chaque carte nous avons associé le pipeline responsable de sa sélection.
Les noms existaient déjà dans le SDK Google, ils ont notamment été publiés récemment par Metehan Yesilyurt. Ce qui manquait, c'est ce qu'ils font en pratique : combien de contenu chacun sélectionne, à combien d'appareils il le montre, à quelle vitesse, et quels domaines il privilégie. C'est ce que nos données révèlent.
Pour chaque pipeline, nous calculons quatre métriques :
- La portée : pourcentage d'appareils qui voient chaque URL par jour
- La vitesse : âge médian des articles au moment de leur apparition
- L'exclusivité : pourcentage d'URLs propres au pipeline
- Le volume : part dans le flux total
La révélation : pas un algorithme, un système à couches
La croyance courante : Discover utilise un algorithme de recommandation. La réalité : c'est un système structuré en six couches fonctionnelles, chacune avec une logique et une audience distinctes.
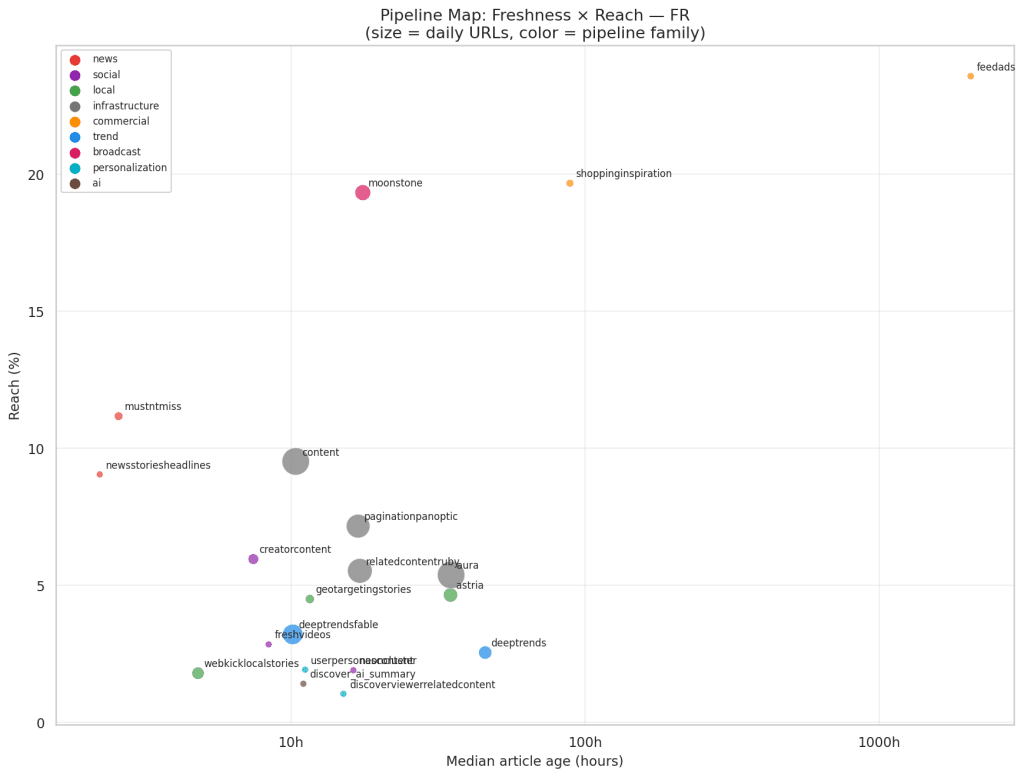
Chaque pipeline positionné par sa vitesse (axe X, log) et sa portée (axe Y). Couleur = famille fonctionnelle. moonstone et shoppinginspiration dominent en portée ; mustntmiss et newsstoriesheadlines sont les plus rapides ; deeptrends et aura persistent le plus longtemps.
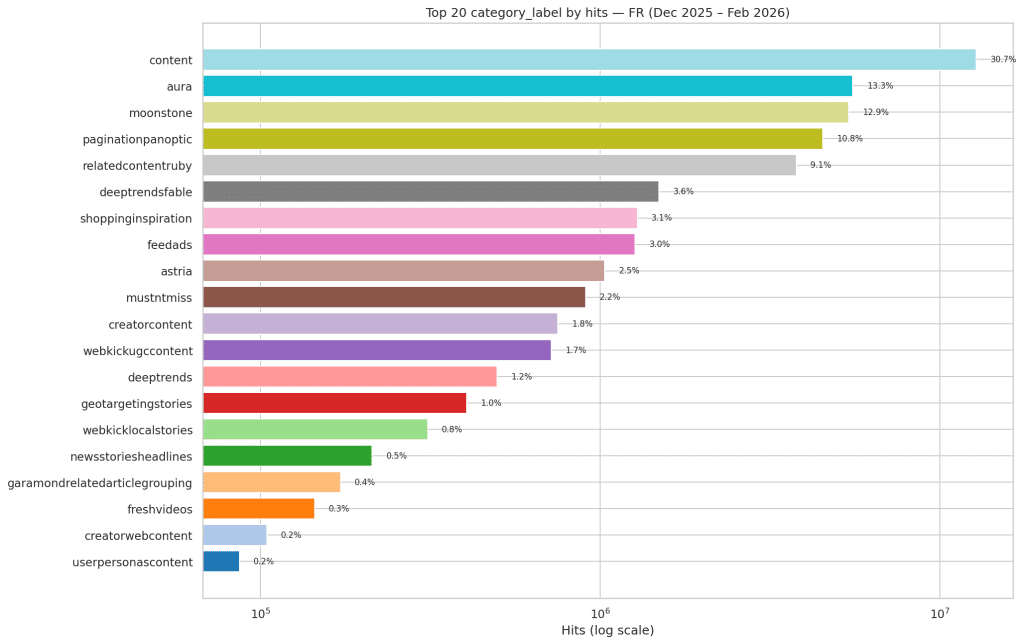
Les 20 pipelines FR classés par volume total. content domine à 30,7 %, suivi d'aura (13,3 %) et moonstone (12,9 %).