Derniers Articles
Les AI Overviews de Google vont enfin débarquer en France Goossips SEO : HTML, Markdown & Sous-répertoires Migration de domaine : Google précise comment utiliser l’outil de « Changement d’adresse » Consultant SEO en agence ou freelance : les 5 actions à mettre en place avant de partir en vacances GEO vs SEO : faut-il choisir ou combiner les deux ? Open Knowledge Format : Google pose les bases d’un nouveau standard pour les agents IA Un tribunal allemand juge Google responsable des erreurs de ses AI Overviews La reconversion à l’ère de l’IA générative : les nouvelles compétences attendues des entreprises Google confirme qu’il ignore le fichier llms.txt et clôt le débat L’édition de juin 2026 de Réacteur est en ligne !Lire l'article complet : Dans les coulisses du classement Google : ce que révèlent les fuites de 2024
Publié le 22/11/2024 à 09:45:07 par Abondance
Dans les coulisses du classement Google : ce que révèlent les fuites de 2024
Mai 2024 restera une date marquante dans l'histoire du référencement naturel. La fuite de plus de 2 500 documents internes de Google a levé le voile sur les mécanismes intimes du moteur de recherche le plus utilisé au monde. Cette documentation technique, comportant plus de 14 000 attributs, vient confirmer, préciser et parfois bousculer des années d'observations empiriques des professionnels du référencement.
Ces révélations s'inscrivent dans la continuité d'autres sources d'information majeures : le leak du Project Veritas en 2019, qui avait déjà fourni quelques documents techniques précieux, et surtout les transcriptions du procès antitrust opposant Google au département de la Justice américaine en 2023. Ces témoignages sous serment d'ingénieurs de Google avaient notamment mis en lumière l'importance cruciale des données comportementales des utilisateurs dans le classement.
La fuite de 2024 va beaucoup plus loin. En donnant accès à la documentation technique de l'API Content Warehouse de Google, elle révèle l'architecture complète du moteur de recherche : des systèmes d'indexation aux algorithmes de classement, en passant par les mécanismes d'évaluation de la qualité. Pour la première fois, nous disposons d'une vue précise sur la manière dont Google organise ses données, les traite et les exploite pour générer ses résultats de recherche.
Le fonctionnement du moteur en trois temps
L'analyse des documents révèle une architecture en trois phases distinctes, que nous avons synthétisée dans une infographie sur le fonctionnement de Google Search d'après le Google Leak. Cette organisation permet à Google d'allier la profondeur de l'analyse à la rapidité de réponse nécessaire pour servir des milliards de requêtes quotidiennes.
Le temps du crawl : la phase off-line
Tout commence avec Trawler, le système principal de crawling qui explore et récupère les pages web. Les documents révèlent l'existence d'un nouveau composant, WebIO, apparu en 2023 pour optimiser la charge du crawl. Ce système mesure avec une granularité extrême - jusqu'à la minute près - chaque connexion sortante, témoignant de l'attention portée par Google à la gestion de ses ressources.
Une fois récupérées, les pages sont réparties entre trois niveaux d'index aux noms évocateurs : Base, Zeppelins et Landfill. Base, stocké en mémoire vive, accueille les pages les plus importantes. Zeppelins, sur disques SSD, héberge les contenus intermédiaires, tandis que Landfill (littéralement "décharge") stocke sur disques durs classiques la grande majorité des pages. Cette hiérarchisation influence jusqu'aux liens : les documents révèlent que les backlinks provenant de sites dans Landfill sont automatiquement considérés comme de faible qualité !
En parallèle s'activent de puissants systèmes d'analyse comme Goldmine et Raffia, véritables usines à metadata qui décortiquent chaque aspect des pages. SAFT (Structured Annotation Framework and Toolkit) cartographie les relations sémantiques, pendant que site2vec - cousin méconnu de word2vec - évalue la cohérence thématique globale des sites.
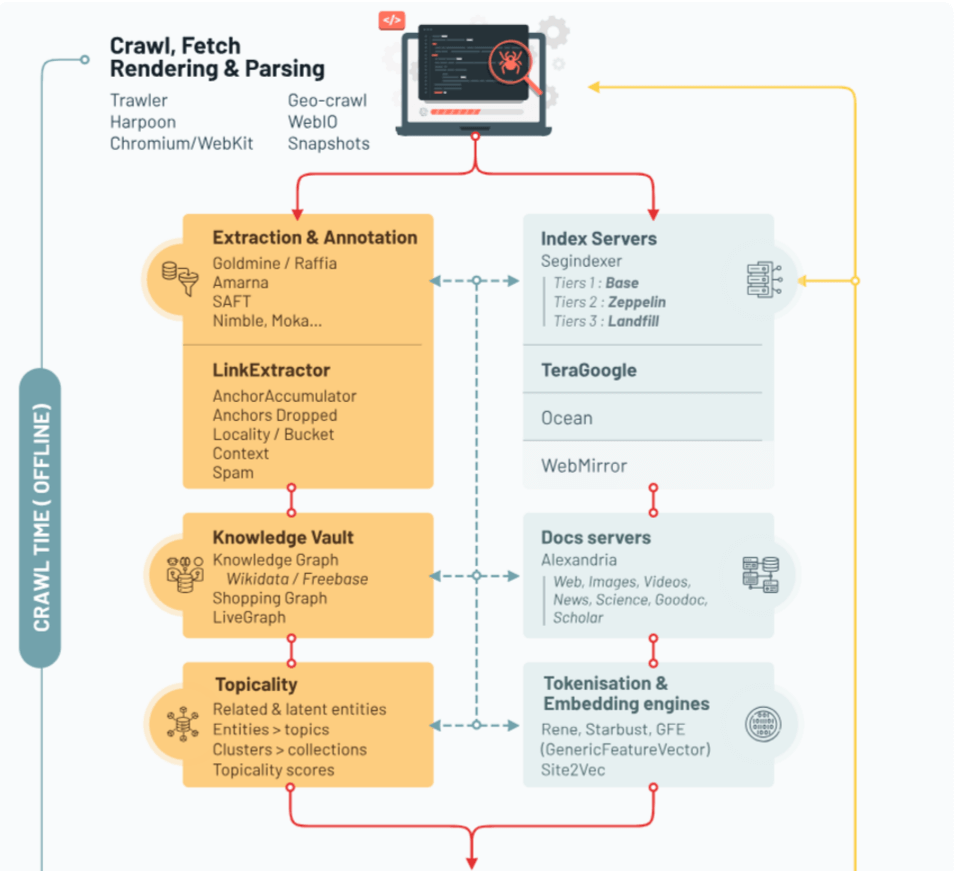
La couche intermédiaire : le merging et l'information retrieval
Entre l'indexation et le temps réel se trouve une couche cruciale dont le...